Hey guys,
Today we're gonna be looking at some Stochastic policy gradient methods. All experiments use the Fourier basis of order 3 to represent the state variable. Jan Peters' Policy Gradient Methods in Robotics is a great review paper!
The focus of this post is on these 3 methods:
1) Monte Carlo Policy Gradient,
2) Policy Gradient by Numerical Gradient Estimate
3) Actor Critic Methods.
*Policy Gradient Methods Python Code*
Why represent the policy directly?
Sometimes the policy is more easily representable compared to the value function. Also it allows us to include continuous actions in a principled manner. For example in the cartpole, representing the Cartpole optimal action using a logistic sigmoid or softmax maybe easier than trying to find the optimal value function.
Policy Gradient by Numerical Gradient Estimate:
Take a look at this paper by UT Austin. They used Numerical gradient Estimation to improve the gait of a robot. This is often the case when we use the numerical methods to estimate the gradient.
Sometimes as the paper mentions, we may not know the true functional form of the policy. In this case we are free to just use the change in reward obtained of the open loop policy and estimate the gradient numerically, since the functional form will be required if we try and find the gradient using analytical methods.
This method is good at improving a reasonably good base policy, but poor at learning from scratch!Nevertheless, it performs satisfactorily on a simple task such as Pole balancing task.
Above image shows how we can estimate the gradient using 2 sided estimate. In the N dimensional case, the derivative becomes the gradient.
We pertrube the policy parameters by delta theta, estimate the reward. We do this many times, and then apply linear regression to estimate the gradient.
Then we move the parameters small direction in the direction of the gradient.
Monte Carlo Policy Gradients:
The Algorithm is Monte Carlo Policy gradient with baseline as the average of the rewards obtained so far. Better baselines are described in Jan peter's linked paper.
The baseline does a good job in reducing the variance, but like all Monte Carlo Methods, sample efficiency becomes a concern.
Actor Critic Methods
In this class of methods, we have both a policy called the actor and the critic, which is a value function.
In this method, unlike the Monte Carlo Method where we use q(s,a) the Monte-Carlo return,
q(s,a) is actually the value function computed by the critic.
Convergence is still guaranteed by the Policy Gradient Theorem, provided we use a compatible approximator.
Recently Deep RL Which uses Policy Gradient methods have becomes famous. We will talk about some of these in future posts.
All in all, policy gradient methods help with continuous action spaces, as in real world robotics actions are mostly continuous, and discretization of the action space may become infeasible after a point of time.
Today we're gonna be looking at some Stochastic policy gradient methods. All experiments use the Fourier basis of order 3 to represent the state variable. Jan Peters' Policy Gradient Methods in Robotics is a great review paper!
The focus of this post is on these 3 methods:
1) Monte Carlo Policy Gradient,
2) Policy Gradient by Numerical Gradient Estimate
3) Actor Critic Methods.
*Policy Gradient Methods Python Code*
Why represent the policy directly?
Sometimes the policy is more easily representable compared to the value function. Also it allows us to include continuous actions in a principled manner. For example in the cartpole, representing the Cartpole optimal action using a logistic sigmoid or softmax maybe easier than trying to find the optimal value function.
Policy Gradient by Numerical Gradient Estimate:
Take a look at this paper by UT Austin. They used Numerical gradient Estimation to improve the gait of a robot. This is often the case when we use the numerical methods to estimate the gradient.
Sometimes as the paper mentions, we may not know the true functional form of the policy. In this case we are free to just use the change in reward obtained of the open loop policy and estimate the gradient numerically, since the functional form will be required if we try and find the gradient using analytical methods.
This method is good at improving a reasonably good base policy, but poor at learning from scratch!Nevertheless, it performs satisfactorily on a simple task such as Pole balancing task.
 |
| Image Courtesy: KineticMaths |
Above image shows how we can estimate the gradient using 2 sided estimate. In the N dimensional case, the derivative becomes the gradient.
We pertrube the policy parameters by delta theta, estimate the reward. We do this many times, and then apply linear regression to estimate the gradient.
Then we move the parameters small direction in the direction of the gradient.
Monte Carlo Policy Gradients:
 |
| MCPG With No Baseline, with Baseline it learns in around 200-300 Episodes |
The Algorithm is Monte Carlo Policy gradient with baseline as the average of the rewards obtained so far. Better baselines are described in Jan peter's linked paper.
The baseline does a good job in reducing the variance, but like all Monte Carlo Methods, sample efficiency becomes a concern.
Actor Critic Methods
In this class of methods, we have both a policy called the actor and the critic, which is a value function.
In this method, unlike the Monte Carlo Method where we use q(s,a) the Monte-Carlo return,
q(s,a) is actually the value function computed by the critic.
Convergence is still guaranteed by the Policy Gradient Theorem, provided we use a compatible approximator.
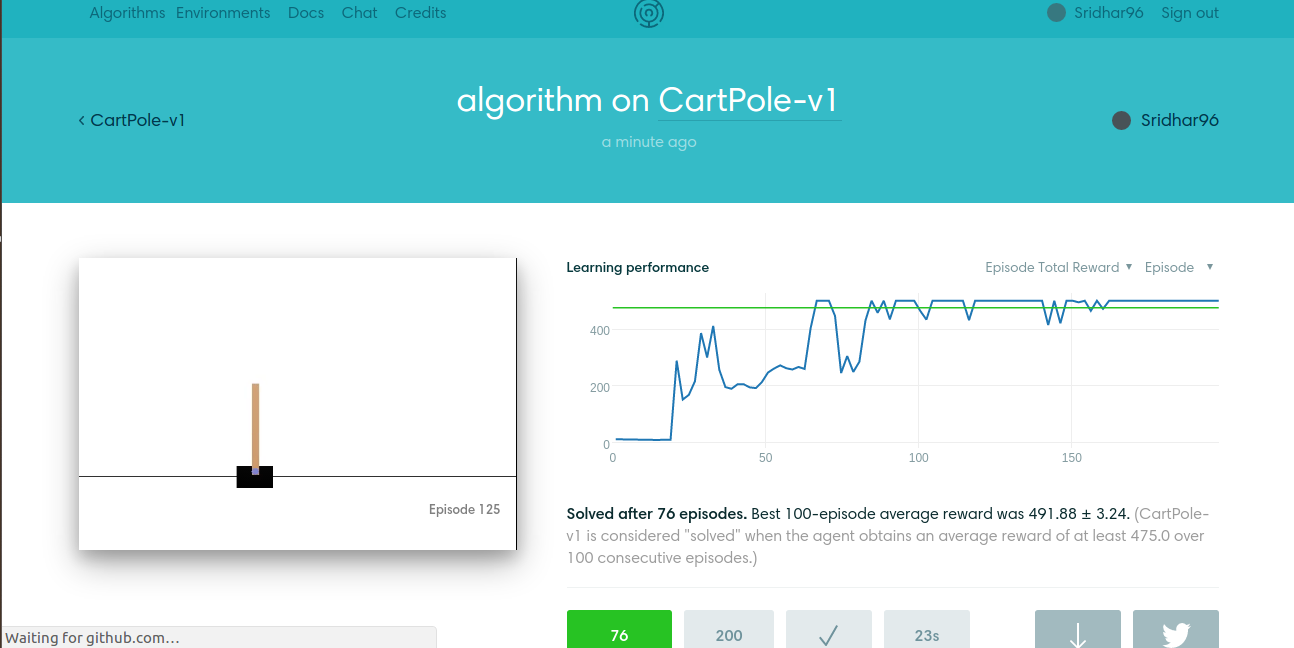 |
| Actor Critic Method on the Cartpole Problem, Softmax Parametrization |
Recently Deep RL Which uses Policy Gradient methods have becomes famous. We will talk about some of these in future posts.
All in all, policy gradient methods help with continuous action spaces, as in real world robotics actions are mostly continuous, and discretization of the action space may become infeasible after a point of time.